

There’s been a lot of hype about Chat GPT, the AI-generated chat tool that is now valued at $29 billion. For sure, the technology underlying Chat GPT and Open AI is impressive. This post is not meant to explain how Chat GPT works, suggest how Chat GPT can be improved, or to criticize Chat GPT for being over-hyped. There are plenty of articles already doing all of those things. (Some of those articles were probably even written by Chat GPT.). The purpose of this article is to show the limitations of machine learning models, especially in situations for which we have little or no intuition.
Try before you buy.
I wanted to see if I could use Chat GPT for a new project I’m working on. It seems like exactly what I need, and if it works it will reduce the level of difficulty by at least 90%. But, as I said, I don’t know the underlying mechanics of the algorithm.
So before I could trust ChatGPT on a totally new project, one for which it would have little or no oversight, I decided to test it out on questions that I know the answer to.
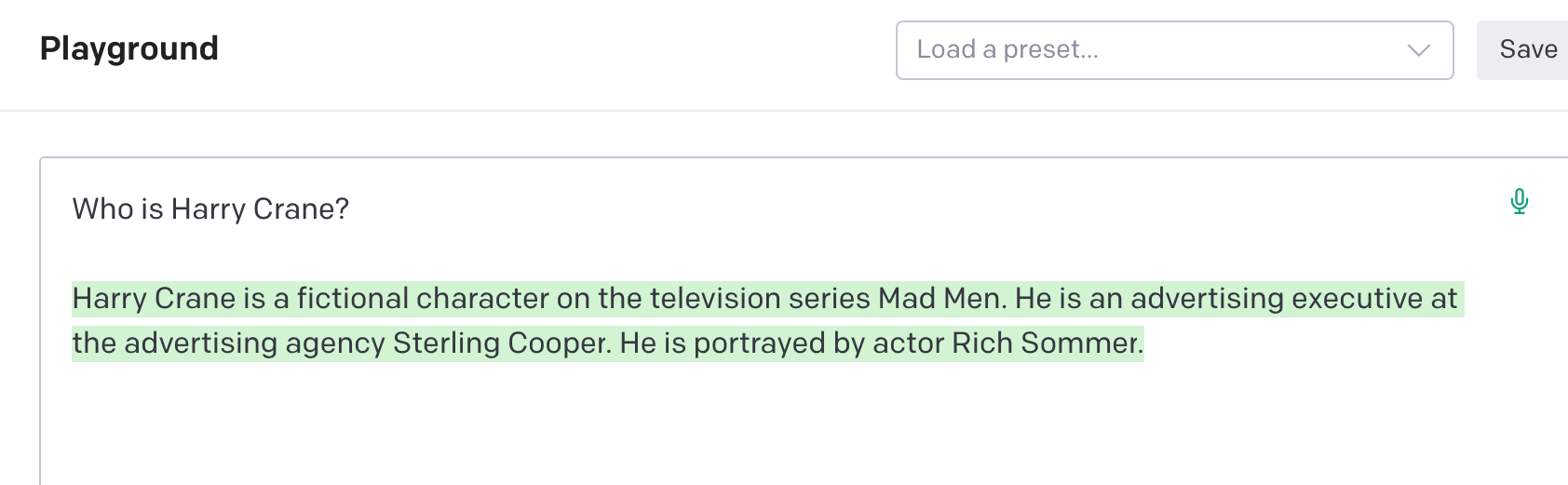
OK, not the answer I was looking for, but not an obviously wrong answer either. At minimum, it proves that the model needs some context in order to zero in on the answer I want. Something to keep in mind.
My next question provides some context:
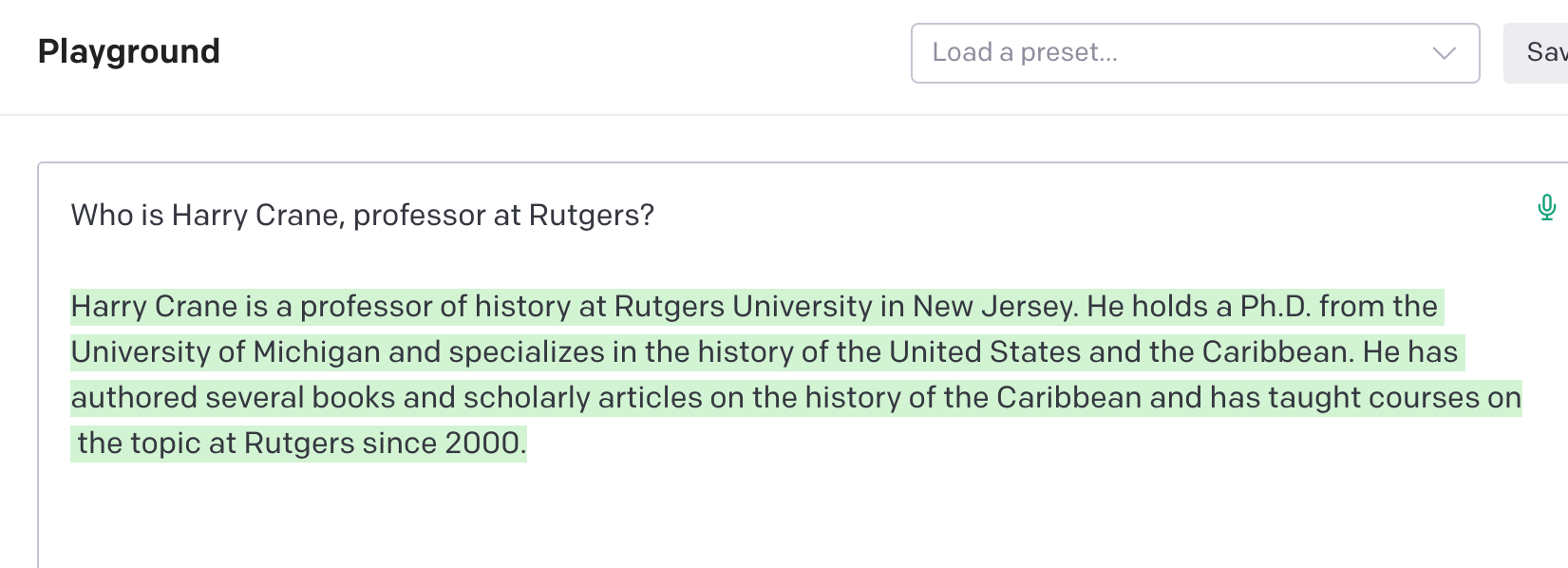
Interesting. I’m not a historian and can find no record of there ever being a historian named Harry Crane at Rutgers. I don’t have a PhD from Michigan. I certainly haven’t written any books or articles on history of the Caribbean, and I haven’t taught at Rutgers since 2000.
But maybe there is a historian somewhere named Harry Crane. Let’s help the algorithm a little more.

Wrong again. I wasn't even born in 1975, and couldn’t have received a PhD by then. I don’t have a PhD from Stanford. I’m not interested in and have never done any research on time series, non-linear time series or Bayesian inference.
Where does it come up with this stuff?
OK, one last try. Since I assume the algorithm is just googling the answers anyway, I’ll tell it exactly where to grab the answers from.

Some of the generic statements here are debatable ("recognized leader"). I’m sure some people would agree with those, while others would disagree. But it’s a pretty safe and generic thing to say about someone with the title of “professor”.
Everything else is just wrong. I haven't authored "several" books, am not director of Rutgers Center for Data Science and Analytics. (I’ve never heard of this supposed center, and a quick search turned up no hits on its existence.) I’ve consulted with some companies, but not the Navy or Google. And I’m not active in any of the listed organizations.
I can’t say for sure, but if I had to guess, I’d say Chat GPT is making stuff up. It really doesn’t matter though, because these answers are obviously wrong.
Rules to live by
If I didn't already know these facts about myself, I would probably think that Harry Crane is a historian from Michigan. But this isn’t just a problem with Chat GPT. It’s a problem with every application of statistics, artificial intelligence, machine learning, data science.
This highlights three key rules for using statistics and data to solve problems.
Rule #1: ML/Statistics is most useful for questions we already know the answer to.
If the model output agrees with the answer we already know to be correct, then it provides external confirmation. Otherwise, we can safely ignore the model because we already know the answer.
Rule #2: ML/Statistics can be useful for problems that we have strong intuition for.
But we still need to be careful. We saw an example of this with Chat GPT above. Suppose we knew that Harry Crane is a statistician, but nothing else. So we know the answer about Harry Crane being a historian wasn’t right. So we provided the extra information about being a statistics professor. This extra intuition wasn’t enough. Even knowing exactly where to look for the information wasn’t enough. If that doesn’t scare you straight, nothing will.
Rule #3: ML/Statistics is useless and can only cause more problems in situations that we have weak intuition or no intuition at all.
A good rule to live by: don’t try to solve problems that you don’t know anything about.
To wrap up, here are a few key takeaways.
Always:
Look at the data.
The output is only as good as the input. Understand where it comes from and how it is being used. Make sure the data is accurate and relevant to the problem. Think about ways it could give misleading or incorrect answers.
Sanity check the output.
Always scrutinize the output. Don’t take it at face value. If it doesn’t make sense, there’s probably something wrong. Zero in on those situations and continually improve the model on those edge cases. If there are too many edge cases, discard the model entirely and start over.
Trust your intuition.
If it doesn’t make intuitive sense, push the pause button. Sometimes our intuition is wrong, but we should require extra evidence to overrule our intuition.
Never:
Use a tool without knowing how it works.
This is tricky because this really limits the number of tools available to us. It’s just not possible to have a deep understanding of how everything works. When it comes to data, we’re better off that way. Understand everything there is to know about a few techniques. It doesn’t matter what it is — regression, clustering, logistic regression, random forests — just know everything you can about it and use that tool on every problem you encounter. Your tool of choice won’t give you the globally optimal (across every data scientist in the world) answer in most cases, but it will give the locally optimal (given your skillset) answer just about every time.
Treat a model as a "blackbox".
Trust anyone who uses the term "blackbox" in anything but a condescending way.
The last two speak for themselves. I submit the above encounter with Chat GPT as Exhibit A.
This makes a lot of sense. It explains why ChatGPT is bad at teaching. In a framework where I have no intuition on how to direct or redirect its responses- the information it gives is often scattershot and seldom foundational.